- Thư mục phần mềm: https://drive.google.com/open?id=1zz-gL_pSF7R_vPXtsygtMMlypnXknA0C&usp=drive_fs
- Phần mềm ký số: https://drive.google.com/open?id=1Bm_2jk9klUhAsgF0ip2gFnQo-DBmyK1F&usp=drive_fs
- Code tách: https://drive.google.com/open?id=1dVfecsQ9Z43gtSeFlfw3cdK7Y8z09NAE&usp=drive_fs
- Hàm check ngày tháng bắt đầu kết thúc Metadata Hoà Bình: =datevalue(R2) - datevalue(Q2) =IF(ISDATE(Q2); IF(TEXT(Q2; "dd/mm/yyyy") = Q2; "Đúng định dạng"; "Sai định dạng"); "Không phải ngày tháng") =IF(ISDATE(R2); IF(TEXT(R2; "dd/mm/yyyy") = R2; "Đúng định dạng"; "Sai định dạng"); "Không phải ngày tháng")
- Lấy 2 từ đầu tiên trong 1 cell: =JOIN(" "; INDEX(SPLIT(Y82; " "); 1; 1); INDEX(SPLIT(Y82; " "); 1; 2))
- Liệt kê file kèm kích thước: "find . -iname "*.pdf" -exec du -k {} \; | sort -k2"
vi ~/.zshrc
PROMPT="%(?:%{$fg_bold[green]%}➜ :%{$fg_bold[red]%}➜ )"
PROMPT+='%{$fg[cyan]%}%~%{$reset_color%} $(git_prompt_info)'
ZSH_THEME_GIT_PROMPT_PREFIX="%{$fg_bold[blue]%}git:(%{$fg[red]%}"
ZSH_THEME_GIT_PROMPT_SUFFIX="%{$reset_color%} "
ZSH_THEME_GIT_PROMPT_DIRTY="%{$fg[blue]%}) %{$fg[yellow]%}✗"
ZSH_THEME_GIT_PROMPT_CLEAN="%{$fg[blue]%})"
Để chạy python: Cài bản đóng gói minianacoda https://docs.conda.io/en/latest/miniconda.html
Mở Anacoda Promt >> Cài thêm một số thư viện theo cấu trúc nếu thiếu như pip install PyPDF4 openpyxl
Liệt kê cấu trúc file và thư mục:
dir "D:\14. TanHoa-A3" /S /B /-C /4 > C:\danhsach.txt
# Nhiều dòng
function Format-Size {
param([int]$bytes)
if ($bytes -gt 1GB) {$size = "{0:N1} GB" -f ($bytes / 1GB)}
else {$size = "{0:N1} MB" -f ($bytes / 1MB)}
return $size
}
$folder = "D:\SOHOA"
$results = Get-ChildItem $folder -Recurse | ForEach-Object {
[PSCustomObject]@{
Size = (Format-Size $_.Length)
Name = $_.FullName
}
}
$results | ForEach-Object {
$line = $_.Size + "`t" + $_.Name
$line | Out-File -Append -Encoding UTF8 -FilePath C:\danhsach.txt
}
# Một dòng
Get-ChildItem "D:\SOHOA" -Recurse | Format-Table @{L="Name";E={$_.FullName}},@{L="Size(MB)";E={if($_.Length -gt 1GB){"{0:N1} GB" -f ($_.Length / 1GB)}elseif($_.Length -gt 1MB){"{0:N1} MB" -f ($_.Length / 1MB)}else{"{0:N0} bytes" -f $_.Length}}} | Out-File C:\List-SoHoa.txt
1. Script đếm số trang A3: https://youtu.be/eDZKeGi-CpU
import os
import openpyxl
from PyPDF4 import PdfFileReader
from datetime import datetime
def count_pdf_files(folder):
pdf_count = 0
for root, dirs, files in os.walk(folder):
for file in files:
if file.endswith('.pdf'):
pdf_count += 1
return pdf_count
# Đường dẫn tuyệt đối đến thư mục chứa tất cả các tệp PDF cần xử lý
pdf_folder = 'C:\\Users\\TTCNTT\\Desktop'
#pdf_folder = '/mnt/d/04. Phường Thịnh Lang'
# Đếm số lượng file PDF trong toàn bộ cây thư mục
total_pdf_files = count_pdf_files(pdf_folder)
# Hàm kiểm tra trang pdf có phải là A3 không và trả về vị trí của trang A3 nếu có
def check_a3_page(pdf_reader, page_num):
page = pdf_reader.getPage(page_num)
page_edges = page.cropBox
left_edge = page_edges.getLowerLeft()
right_edge = page_edges.getLowerRight()
top_edge = page_edges.getUpperLeft()
bottom_edge = page_edges.getLowerLeft()
width = abs(right_edge[0] - left_edge[0])
height = abs(top_edge[1] - bottom_edge[1])
#print (f"trang: {page_num+1}, size: {width} x {height}, sub: {width-height} ")
#if (width >= 600 and height >= 900 and width > height) or (width >= 900 and height >= 600 and width < height):
if abs(width - height) >= 300:
return page_num+1
else:
return None
# Hàm đếm số trang A3 của file pdf và trả về một list vị trí của các trang A3
def count_a3_pages(file_path):
with open(file_path, 'rb') as f:
pdf_reader = PdfFileReader(f)
page_count = pdf_reader.getNumPages()
a3_count = 0
a3_pages = []
for page_num in range(page_count):
a3_page_num = check_a3_page(pdf_reader, page_num)
if a3_page_num is not None:
a3_count += 1
a3_pages.append(a3_page_num)
return a3_count, a3_pages
# Lấy tên thư mục cha và thêm ".xlsx" vào tên
excel_file_name = os.path.basename(os.path.normpath(pdf_folder)) + '.xlsx'
print(f'Bắt đầu đếm A3 thư mục: {pdf_folder}')
print('Điều kiện thoả trang A3 là: abs(width - height) >= 300')
print('')
# Tạo workbook mới
workbook = openpyxl.Workbook()
worksheet = workbook.active
worksheet.title = 'Page Count'
# Ghi header cho bảng
worksheet.cell(row=1, column=1, value='File Order')
worksheet.cell(row=1, column=2, value='File Path')
worksheet.cell(row=1, column=3, value='Total Pages')
worksheet.cell(row=1, column=4, value='A3 Page Count')
worksheet.cell(row=1, column=5, value='A3 Page Position')
# total_a3_pages = 0
# total_total_pages = 0
def process_pdf_files(pdf_folder):
row_num = 2 # Bắt đầu ghi từ hàng thứ 2
total_a3_pages = 0 # Khởi tạo tổng số trang A3
total_pages = 0
total_total_pages = 0
# đối tượng datetime chứa ngày và giờ hiện tại
hientai = datetime.now().strftime("%d/%m/%Y %H:%M:%S")
for root, dirs, files in os.walk(pdf_folder):
for file in files:
if file.endswith('.pdf'):
file_path = os.path.join(root, file)
abs_file_path = os.path.abspath(file_path) # Lấy đường dẫn tuyệt đối của file PDF
try:
with open(file_path, 'rb') as f:
pdf_reader = PdfFileReader(f)
total_pages = pdf_reader.getNumPages()
a3_count, a3_pages = count_a3_pages(file_path)
total_a3_pages += a3_count
total_total_pages += total_pages
# Ghi dữ liệu vào bảng
worksheet.cell(row=row_num, column=1, value=f'{row_num - 1}/{total_pdf_files}')
worksheet.cell(row=row_num, column=2, value=abs_file_path)
worksheet.cell(row=row_num, column=3, value=total_pages)
worksheet.cell(row=row_num, column=4, value=a3_count)
worksheet.cell(row=row_num, column=5, value=','.join(map(str, a3_pages)))
# In thông tin số thứ tự, đường dẫn tuyệt đối, số trang A3 của từng tập tin
print(f'Pdf thứ: {row_num - 1}/{total_pdf_files}; {abs_file_path}; Số trang A3: {a3_count}/{total_pages}; Vị trí A3: {a3_pages}')
row_num += 1
except Exception as e:
print(f"Error processing file {file_path}: {e}")
continue
# Ghi dữ liệu Tong vào cuoi bảng
worksheet.cell(row=row_num, column=1, value="Tổng")
worksheet.cell(row=row_num, column=3, value=total_total_pages)
worksheet.cell(row=row_num, column=4, value=total_a3_pages)
worksheet.cell(row=row_num, column=5, value=hientai)
# Tong quy ra A4
worksheet.cell(row=row_num+1, column=3, value=(total_total_pages+total_a3_pages))
# In thông tin tổng số trang A3 của toàn bộ thư mục
print(f'Total A3 pages/ Total pages: {total_a3_pages}/{total_total_pages} = {total_a3_pages+total_total_pages}')
process_pdf_files(pdf_folder)
# Lưu file Excel trong cùng thư mục chứa script Python
excel_file_path = excel_file_name
workbook.save(excel_file_path)
print(f"File được lưu tại: {excel_file_path}")
Check trang trắng V1
import openpyxl
import fitz
import os
def delete_blank_pages(xlsx_file):
wb = openpyxl.load_workbook(xlsx_file)
sheet = wb.active
for row in sheet.iter_rows(min_row=2, values_only=True):
pdf_path = row[0]
blank_pages = [int(page) for page in row[1].split(',')]
try:
doc = fitz.open(pdf_path)
# Sắp xếp danh sách trang trắng theo thứ tự tăng dần
blank_pages.sort()
for page_number in reversed(blank_pages):
doc.delete_page(page_number - 1)
print(f"Đã xoá trang: {page_number - 1}")
temp_path = os.path.splitext(pdf_path)[0] + "_temp.pdf"
doc.save(temp_path, garbage=4, deflate=True, clean=True)
doc.close()
os.replace(temp_path, pdf_path)
print(f"Đã xoá trang trắng từ {pdf_path}. Kết quả được ghi đè lên tệp {pdf_path}")
except (fitz.errors.PDFInvalidError, FileNotFoundError) as e:
print(f"Lỗi khi xử lý tệp {pdf_path}: {str(e)}")
wb.close()
xlsx_file = "/mnt/c/Users/TTCNTT/Desktop/script/TT.CGCN_2023-03-02.020.xlsx"
delete_blank_pages(xlsx_file)
2. Kiểm tra xuất ra danh sách các trang trắng
import os
import PyPDF4
import openpyxl
from PIL import Image
from pdf2image import convert_from_path
import pytesseract
import fitz
def check_blank_pages(pdf_file):
blank_pages = 0
total_pages = 0
blank_page_positions = []
with fitz.open(pdf_file) as doc:
total_pages = doc.page_count
for page_num in range(total_pages):
page = doc.load_page(page_num)
# Convert PDF page to image
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
# Convert image to grayscale for OCR
img_gray = img.convert('L')
# Use Pytesseract to extract text from the image
text = pytesseract.image_to_string(img_gray)
# Check if the extracted text is blank
if not text.strip():
blank_pages += 1
print(f"{pdf_file}, đọc trang: {page_num+1}/{total_pages} ==> page {page_num+1} (là trang trắng)")
blank_page_positions.append(str(page_num + 1))
else:
print(f"{pdf_file}, đọc trang: {page_num+1}/{total_pages}")
blank_page_positions_str = ', '.join(blank_page_positions)
return blank_pages, total_pages, blank_page_positions_str
# Rest of the code remains the same
#folder_path = '/mnt/g/Shared drives/TNMT_HoaBinh3/3.BAN_GIAO/11.YEN_MONG/6.TK/HOP1/YM.TK_001.07.05.H28_2010.1/'
folder_path = '/mnt/c/Users/TTCNTT/Desktop/HN.CGCN_HOP01/test/'
pdf_files = []
for root, dirs, files in os.walk(folder_path):
for f in files:
if f.endswith('.pdf'):
pdf_files.append(os.path.join(root, f))
data = {
#'Thư mục': [],
'Tên file': [],
'Danh sách Blank': [],
'Tổng số trang': [],
'Số trang trắng': [],
'Tỉ lệ': [],
}
file_count = 0
total_blank_pages = 0
total_pages = 0
for pdf_file in pdf_files:
try:
pdf_folder = os.path.dirname(pdf_file)
pdf_folder_name = os.path.basename(pdf_folder)
print(f"Bắt đầu check file: {pdf_folder_name}/{os.path.basename(pdf_file)}")
blank_pages, num_pages, blank_page_positions_str = check_blank_pages(pdf_file)
file_count += 1
total_blank_pages += blank_pages
total_pages += num_pages
#data['Thư mục'].append(pdf_folder)
data['Tên file'].append(pdf_folder + "/" + os.path.basename(pdf_file))
data['Danh sách Blank'].append(blank_page_positions_str)
data['Tổng số trang'].append(num_pages)
data['Số trang trắng'].append(blank_pages)
data['Tỉ lệ'].append(f"{(blank_pages/num_pages) * 100:.2f}%") # Chuyển tỉ lệ thành phần trăm
if total_pages != 0:
if blank_page_positions_str != '':
print(f"File: {pdf_folder_name}/{os.path.basename(pdf_file)} => có danh sách trang trắng: {blank_page_positions_str}")
else:
print(f"File: {pdf_folder_name}/{os.path.basename(pdf_file)} => không có trang trắng.")
print("------------------------------------------------------------------")
except PyPDF4.utils.PdfReadError:
print(f"Không thể đọc file {os.path.basename(pdf_file)}")
continue
#print(f"Tổng số trang trắng: {total_blank_pages}/{total_pages} ({total_blank_pages/total_pages:.2%})")
print()
print("##################################################################")
if total_pages != 0:
percentage = total_blank_pages / total_pages
print(f"Tổng số trang trắng của thư mục: {total_blank_pages}/{total_pages} ({percentage:.2%})")
else:
print("Không có trang trắng trong tệp PDF.")
wb = openpyxl.Workbook()
ws = wb.active
headers = ['Tên file', 'Danh sách Blank','Tổng số trang', 'Số trang trắng', 'Tỉ lệ']
ws.append(headers)
for i in range(len(data['Tên file'])):
row_data = [data['Tên file'][i],data['Danh sách Blank'][i], data['Tổng số trang'][i], data['Số trang trắng'][i], data['Tỉ lệ'][i]]
ws.append(row_data)
wb.save('TT.CGCN_2023-03-02.020.xlsx')
print("Kết quả đã được lưu vào file TT.CGCN_2023-03-02.020.xlsx")
print("##################################################################")
print()
3. Xoá các trang trắng bằng Python vòng 1
import openpyxl
import fitz
import os
def delete_blank_pages(xlsx_file):
wb = openpyxl.load_workbook(xlsx_file)
sheet = wb.active
for row in sheet.iter_rows(min_row=2, values_only=True):
pdf_path = row[0]
blank_pages = [int(page) for page in row[1].split(',')]
try:
doc = fitz.open(pdf_path)
# Sắp xếp danh sách trang trắng theo thứ tự tăng dần
blank_pages.sort()
for page_number in reversed(blank_pages):
doc.delete_page(page_number - 1)
print(f"Đã xoá trang: {page_number - 1}")
temp_path = os.path.splitext(pdf_path)[0] + "_temp.pdf"
doc.save(temp_path, garbage=4, deflate=True, clean=True)
doc.close()
os.replace(temp_path, pdf_path)
print(f"Đã xoá trang trắng từ {pdf_path}. Kết quả được ghi đè lên tệp {pdf_path}")
except (fitz.errors.PDFInvalidError, FileNotFoundError) as e:
print(f"Lỗi khi xử lý tệp {pdf_path}: {str(e)}")
wb.close()
xlsx_file = "/mnt/c/Users/TTCNTT/Desktop/script/TT.CGCN_2023-03-02.020.xlsx"
delete_blank_pages(xlsx_file)
Bài toán đặt tên file chèn thêm vào thư mục cũ:
Năm 2022 có scan nhưng chỉ có A4, Năm 2023 mới scan A3. Sau khi nhập liệu và tách xong năm 2023, làm sao để nhồi văn bản đã tách vào đúng thư mục và số thứ tự tiếp theo (last) của từng hồ sơ nếu scan thêm
Bước 1: Dùng đoạn code sau để đếm tổng số file pdf của thư mục (cột B) và lấy số văn bản cuối cùng (trích giữa hai dấu chấm cuối cùng của tên file) + 1 ghi vào cột C
- Thư mục: Cột A
- Tổng số file: Cột B
- Tổng thứ tự tiếp theo của văn bản: Cột C
import os
import pandas as pd
import re
def count_and_extract_numbers(directory):
result = []
for root, _, files in os.walk(directory):
pdf_files = [file for file in files if file.lower().endswith('.pdf')]
folder_name = os.path.basename(root)
pdf_count = len(pdf_files)
max_number = 0
for file in pdf_files:
match = re.search(r'(\d+)\.pdf$', file)
if match:
number = int(match.group(1))
max_number = max(max_number, number)
result.append((folder_name, pdf_count, max_number + 1))
return result
def write_to_excel(data, output_file):
df = pd.DataFrame(data, columns=['Folder', 'PDF Count', 'Max Number + 1'])
df.to_excel(output_file, index=False)
# Đường dẫn thư mục bạn muốn đếm file PDF và trích xuất số
directory_path = '/mnt/d/03. Phường Đồng Tiến/DongTien_VanBan'
# Tên file Excel đầu ra
output_file = 'last_van_ban_.xlsx'
# Đếm số lượng file PDF và trích xuất số, sau đó ghi vào file Excel
result = count_and_extract_numbers(directory_path)
write_to_excel(result, output_file)
print('Đã ghi kết quả vào file Excel:', output_file)
Bài toán gộp file pdf trong thư mục năm 2022:
Yêu cầu đặt ra là gộp tất cả các file trong một thư mục hồ sơ thành một file pdf hồ sơ
Mục đích dùng để đẩy lên Google Drive và gán link thuận lợi cho việc tìm kiếm khi tra cứu
Đoạn code sau thực hiện việc trên (Tên file trong thư mục được sắp xếp, nếu tên file có chứa 'MLTL' hoặc 'BIA' thì file BIA được cho lên trước xong đến MLTL rồi đến các file văn bản khác được sắp xếp)
import os
from pdfrw import PdfWriter, PdfReader
def merge_pdfs_in_directory(directory):
writer = PdfWriter()
bia_files = []
mltl_files = []
other_files = []
for filename in os.listdir(directory):
filepath = os.path.join(directory, filename)
if os.path.isfile(filepath) and filename.lower().endswith('.pdf'):
if 'BIA' in filename:
bia_files.append(filepath)
elif 'MLTL' in filename:
mltl_files.append(filepath)
else:
other_files.append(filepath)
bia_files = sorted(bia_files, key=lambda x: os.path.basename(x))
mltl_files = sorted(mltl_files, key=lambda x: os.path.basename(x))
other_files = sorted(other_files, key=lambda x: os.path.basename(x))
pdf_files = bia_files + mltl_files + other_files
if pdf_files:
for filepath in pdf_files:
reader = PdfReader(filepath)
writer.addpages(reader.pages)
first_file_name = os.path.splitext(os.path.basename(pdf_files[0]))[0]
#new_merged_filename = first_file_name[:-4] + '.pdf'
parts = first_file_name.split('.')
if len(parts) >= 3:
new_parts = parts[:-1] # Lấy từ đầu cụm tên đến trước dấu chấm thứ 2 từ cuối về
new_filename = '.'.join(new_parts) + '._all.pdf'
else:
new_filename = first_file_name
merged_filepath = os.path.join(directory, new_filename)
#merged_filepath = os.path.join(directory, new_merged_filename)
writer.write(merged_filepath)
print('Đã tạo thành công tệp PDF gộp tại:', merged_filepath)
for subdir in os.listdir(directory):
subdir_path = os.path.join(directory, subdir)
if os.path.isdir(subdir_path):
merge_pdfs_in_directory(subdir_path)
root_directory = '/mnt/d/02. Phường Tân Hòa/'
merge_pdfs_in_directory(root_directory)
Sau khi đã tạo file gộp làm sao để lấy link file pdf này để gán vào cột link tương ứng với từng file => Mục đích để tìm 1 sơ Ctrl + Click trên file exel thì bật ra trên Browser file ghép mà đã đẩy lên Drive ở bước trước.
Đoạn AppScript này thực hiện việc lấy link pdf của tất cả các file trong 1 thư mục khi truyền vào ID của nó. Kết quả trả ra là 1 sheet gồm 2 cột: Tên file; Link drive của file.
Khi chạy được link này dùng vloopkup đẩy ra link tương ứng với từng file pdf của hồ sơ tương ứng.
function getAllPDFFiles() {
var parentFolderId = "1xC7oNVF5jTxruho0Vk_jsNbUpdpsYlPW"; // Tách Quỳnh Lâm
var sheetName = "link_drive"; // Tên sheet để ghi liên kết
var parentFolder = DriveApp.getFolderById(parentFolderId);
var pdfFiles = [];
// Đệ quy lấy tất cả các tệp PDF trong thư mục cha và các thư mục con
function getAllPDFFilesInFolder(folder) {
var files = folder.getFiles();
while (files.hasNext()) {
var file = files.next();
if (file.getMimeType() === "application/pdf") {
pdfFiles.push({ name: file.getName(), link: file.getUrl() });
}
}
var subFolders = folder.getFolders();
while (subFolders.hasNext()) {
var subFolder = subFolders.next();
getAllPDFFilesInFolder(subFolder);
}
}
getAllPDFFilesInFolder(parentFolder);
// Ghi các liên kết vào sheet trên Google Sheets
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName(sheetName);
sheet.clear();
var data = pdfFiles.map(function(file) {
return [file.name, file.link, "=HYPERLINK(\"" + file.link + "\"; \"Link file hồ sơ\")"];
});
sheet.getRange(1, 1, data.length, data[0].length).setValues(data);
;
Logger.log("Đã ghi các liên kết vào sheet 'link_van_ban'");
}
/** // Dùng API Google Drive nhưng không hiệu quả khi gọi nhiều
function getAllPDFFiles_v2() {
var parentFolderId = "1xC7oNVF5jTxruho0Vk_jsNbUpdpsYlPW"; // Tách Quỳnh Lâm
var sheetName = "link_drive"; // Tên sheet để ghi liên kết
var pageSize = 100; // Kích thước trang (số file xử lý trong mỗi lần)
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName(sheetName);
var startTime = new Date().getTime(); // Thời điểm bắt đầu thực thi
var pageToken = ''; // Token trang để duyệt qua các trang kết quả
var totalCount = 0; // Số lượng file đã xử lý
do {
// Lấy danh sách tệp PDF trong thư mục cha với pageSize và pageToken
var response = Drive.Files.list({
corpora: "drive",
driveId: "0AOeTrzDrBHWzUk9PVA",
includeItemsFromAllDrives: true,
supportsAllDrives: true,
q: "mimeType='application/pdf' and '" + parentFolderId + "' in parents",
fields: "nextPageToken, items(title, downloadUrl)",
pageSize: pageSize,
pageToken: pageToken
});
var files = response.items;
// Ghi danh sách tệp PDF vào sheet
files.forEach(function(file) {
var name = file.title;
var link = file.downloadUrl;
sheet.appendRow([name, link, "Đã xử lý"]);
});
totalCount += files.length;
// Cập nhật pageToken cho lần duyệt tiếp theo
pageToken = response.nextPageToken;
// Nghỉ 1 giây trước khi tiếp tục xử lý phần tiếp theo
Utilities.sleep(1000);
} while (pageToken);
var endTime = new Date().getTime(); // Thời điểm kết thúc thực thi
var executionTime = (endTime - startTime) / 1000; // Thời gian thực thi (đổi sang giây)
Logger.log("Thời gian bắt đầu: " + new Date(startTime));
Logger.log("Thời gian thực thi: " + executionTime + " giây");
Logger.log("Tổng số file đã xử lý: " + totalCount);
Logger.log("Đã ghi các liên kết vào sheet 'link_drive'");
}
*/Quản lý tài liệu điện tử (AXDMS): 27.72.56.125:8142\admin\123456 (toannck32@wru.vn)
Lấy link trên Google Drive các file trong một thư mục
function getAllPDFFiles() {
var parentFolderId = "1GJK5prBUEtojQWxMHghp0LYN5GJ8F3_H"; // ID của Hồ sơ tách Tân Thịnh
//var parentFolderId = "18gqYDfgnjU5nfecr53Hak00B-42aTrjw"; // ID của Văn bản Tân Thịnh
var sheetName = "Link_file_pdf"; // Tên sheet để ghi liên kết
var parentFolder = DriveApp.getFolderById(parentFolderId);
var pdfFiles = [];
// Đệ quy lấy tất cả các tệp PDF trong thư mục cha và các thư mục con
function getAllPDFFilesInFolder(folder) {
var files = folder.getFiles();
while (files.hasNext()) {
var file = files.next();
if (file.getMimeType() === "application/pdf") {
pdfFiles.push({ name: file.getName(), link: file.getUrl() });
}
}
var subFolders = folder.getFolders();
while (subFolders.hasNext()) {
var subFolder = subFolders.next();
getAllPDFFilesInFolder(subFolder);
}
}
getAllPDFFilesInFolder(parentFolder);
// Ghi các liên kết vào sheet trên Google Sheets
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName(sheetName);
sheet.clear();
var data = pdfFiles.map(function(file) {
return [file.name, file.link, "=HYPERLINK(\"" + file.link + "\"; \"Link file hồ sơ\")"];
});
sheet.getRange(1, 1, data.length, data[0].length).setValues(data);
;
Logger.log("Đã ghi các liên kết vào sheet 'link_van_ban'");
}
function authenticateAndCallAPI() {
var clientId = "588877609704-u2m18invj7ifft5nmr37gbff7apqht1h.apps.googleusercontent.com";
var clientSecret = "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";
var scope = "https://www.googleapis.com/auth/drive.readonly";
var service = getService(clientId, clientSecret, scope);
if (service.hasAccess()) {
// Đã xác thực thành công
// Gọi các phương thức của Google Drive API ở đây
getAllPDFFilesDriveAPI();
} else {
// Chưa xác thực hoặc gặp lỗi xác thực
var authorizationUrl = service.getAuthorizationUrl();
Logger.log('Xác thực: Vui lòng truy cập vào URL sau và cấp quyền truy cập cho ứng dụng:\n' + authorizationUrl);
}
}
function getService(clientId, clientSecret, scope) {
return OAuth2.createService('drive')
.setAuthorizationBaseUrl('https://accounts.google.com/o/oauth2/auth')
.setTokenUrl('https://accounts.google.com/o/oauth2/token')
.setClientId(clientId)
.setClientSecret(clientSecret)
.setScope(scope)
.setCallbackFunction('authCallback')
.setPropertyStore(PropertiesService.getUserProperties());
}
function authCallback(request) {
var service = getService();
var authorized = service.handleCallback(request);
if (authorized) {
return HtmlService.createHtmlOutput('Xác thực thành công! Bạn có thể đóng cửa sổ này.');
} else {
return HtmlService.createHtmlOutput('Xác thực không thành công! Bạn có thể đóng cửa sổ này và thử lại sau.');
}
}
function getAllPDFFilesDriveApi() {
var parentFolderId = "1GJK5prBUEtojQWxMHghp0LYN5GJ8F3_H";
var sheetName = "Link_file_pdf";
var pdfFiles = [];
// Gọi Google Drive API để lấy danh sách tệp PDF
function getAllPDFFilesFromAPI() {
var pageToken = null;
do {
var response = Drive.Files.list({
q: "mimeType='application/pdf' and '" + parentFolderId + "' in parents",
fields: "items(id,title,webContentLink),nextPageToken",
pageToken: pageToken
});
var files = response.items;
if (files && files.length > 0) {
for (var i = 0; i < files.length; i++) {
var file = files[i];
pdfFiles.push({ name: file.title, link: file.webContentLink });
}
}
pageToken = response.nextPageToken;
} while (pageToken);
}
// Ghi các liên kết vào sheet trên Google Sheets
function writeDataToSheet() {
var sheet = SpreadsheetApp.getActiveSpreadsheet().getSheetByName(sheetName);
sheet.clear();
var data = pdfFiles.map(function(file) {
return [file.name, file.link, "=HYPERLINK(\"" + file.link + "\"; \"Link file hồ sơ\")"];
});
sheet.getRange(1, 1, data.length, data[0].length).setValues(data);
}
// Xác thực và gọi Google Drive API
var service = Drive.Files;
var optionalArgs = { authorization: true, muteHttpExceptions: true };
getAllPDFFilesFromAPI();
writeDataToSheet();
Logger.log("Đã ghi các liên kết vào sheet 'Link_file_pdf'");
}
Đổi tên thư mục và tên file theo công văn mới
import os
import shutil
def rename_pdf_files(directory):
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith('.pdf'):
old_name = os.path.join(root, file)
dirname = os.path.dirname(old_name)
filename = os.path.basename(old_name)
arr = filename.split('_', 1)
print(arr)
if len(arr) == 2:
suffix = arr[0]
ten = arr[1]
new_suffix = suffix.replace('_', '')
new_arr = ten.split('.')
new_arr.insert(len(new_arr) - 2, new_suffix)
reslut = '.'.join(new_arr).replace('_', '.').replace('07.05.H28', '06.05.H28')
new_name = os.path.join(dirname,reslut)
os.rename(old_name, new_name)
print(f"Đã đổi tên từ '{old_name}' sang '{new_name}'")
for root, dirs, files in os.walk(directory):
for dir_name in dirs:
if "_" in dir_name and "." in dir_name:
old_path = os.path.join(root, dir_name)
foldername = os.path.basename(old_path)
arr_f = foldername.split('_', 1)
print(arr_f)
if len(arr_f) == 2:
suffix_f = arr_f[0]
ten_f = arr_f[1]
new_suffix_f = suffix_f.replace('_', '')
new_arr_f = ten_f.split('.')
new_arr_f.append(new_suffix_f)
reslutf = '.'.join(new_arr_f).replace('_', '.').replace('07.05.H28', '06.05.H28')
new_path = os.path.join(root, reslutf)
shutil.move(old_path, new_path)
print(f"Đã đổi tên từ '{old_path}' thành '{new_path}'")
# Thay đổi đường dẫn thư mục tại đây
directory = '.'
rename_pdf_files(directory)
Getpath:
- Đọc file pdf trong một thư mục cho vào biến Dict_pdf là cặp giá trị: Tên file pdf - Đường dẫn tuyệt đối của nó
- Đọc dòng từ 1 file text id.txt (copy từ cột AA của metadata) rồi so khớp với Dict_pdf, nếu khớp thì chèn sau dòng đấy cách bởi ký tự tab (mục đích copy vào exel cho nhanh), không khớp ghi "Ko có"
import os
import openpyxl
def main():
# Đường dẫn đến thư mục chứa file PDF
pdf_folder = '/mnt/e/TNMT_Signed/Tong/1.TAN_THINH_signed'
# Đường dẫn đến file id.txt
id_file_path = '/mnt/c/Users/Thinkpad/Desktop/script_54/id.txt'
# Tạo một Dictionary để lưu tên file và đường dẫn tuyệt đối
dict_pdf = {}
# Duyệt qua thư mục chứa file PDF và các thư mục con
for root, dirs, files in os.walk(pdf_folder):
for file in files:
if file.lower().endswith('.pdf'):
pdf_path = os.path.join(root, file)
dict_pdf[file] = pdf_path
print(f"Thêm vào dict_pdf: {file} - {pdf_path}")
# In số lượng biến tên file PDF trong thư mục
print(f"Số biến của dict_pdf: {len(dict_pdf)}")
print(f"---------------------------------------------")
total_matched = 0 # Biến để đếm tổng số key có path
total_lines = 0 # Biến để đếm tổng số dòng
total_not_matched = 0 # Biến để đếm tổng số dòng không khớp path
try:
# Đọc dữ liệu từ file id.txt
with open(id_file_path, 'r') as id_file:
id_list = id_file.read().splitlines()
except FileNotFoundError:
print(f"Không tìm thấy file {id_file_path}. Vui lòng kiểm tra lại đường dẫn.")
return
except Exception as e:
print(f"Có lỗi xảy ra khi đọc file {id_file_path}: {e}")
return
# Cập nhật dữ liệu trong file id.txt
updated_lines = []
for line_number, row_id in enumerate(id_list, start=1):
total_lines += 1
file_name = f"{row_id}.pdf" # Tên file kết hợp với ".pdf"
if file_name in dict_pdf:
pdf_path = dict_pdf[file_name] # Đường dẫn tuyệt đối tương ứng
pdf_path_windows = os.path.normpath(pdf_path) # Chuyển đổi đường dẫn sang dạng kiểu Windows
updated_lines.append(f"{row_id}\t{pdf_path_windows}\n")
total_matched += 1
else:
updated_lines.append(f"{row_id}\tKo có\n") # Ghi "Ko có" khi không khớp
total_not_matched += 1
print(f"File: {row_id} (dòng: {line_number}) => không khớp")
# Ghi dữ liệu đã cập nhật vào file id.txt
try:
with open(id_file_path, 'w') as id_file:
id_file.writelines(updated_lines)
except Exception as e:
print(f"Có lỗi xảy ra khi ghi file {id_file_path}: {e}")
# In số tổng số key có path trên tổng số dòng và tổng số dòng không khớp path
print(f"---------------------------------------------")
print(f"Tổng có path / Tổng dòng: {total_matched} / {total_lines}")
print(f"Số dòng không khớp: {total_not_matched}")
print(f"---------------------------------------------")
if __name__ == "__main__":
main()
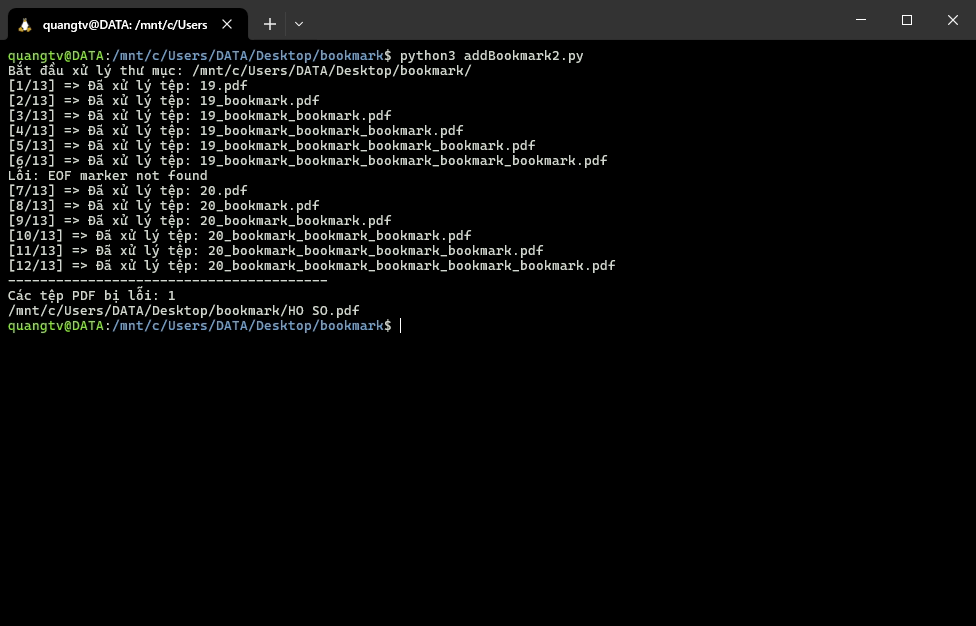
Thêm bookmark vào các file pdf trong 1 thư mục với tên file mới _bookkmark.pdf
from PyPDF2 import PdfReader, PdfWriter
import os
# Khởi tạo danh sách error_files trước khi sử dụng nó
error_files = []
def add_pdf_name_as_bookmark(input_pdf_path, output_dir, file_count, total_files):
try:
# Lấy tên tệp PDF từ đường dẫn
pdf_name = os.path.basename(input_pdf_path)
# Tạo tên tệp đầu ra bằng cách thêm "_bookmark" vào tên tệp đầu vào
output_pdf_path = os.path.join(output_dir, os.path.splitext(pdf_name)[0] + "_bookmark.pdf")
# Đọc tài liệu PDF gốc
pdf_reader = PdfReader(input_pdf_path)
# Tạo đối tượng PdfWriter cho tài liệu PDF mới
pdf_writer = PdfWriter()
# Duyệt qua từng trang trong tài liệu PDF gốc
for page_num in range(len(pdf_reader.pages)):
pdf_reader_page = pdf_reader.pages[page_num]
# Đặt tên cho Bookmark là tên tệp PDF
bookmark_title = pdf_name
# Tạo đối tượng Bookmark
pdf_writer.add_outline_item(bookmark_title, page_num)
# Thêm trang từ tài liệu gốc vào tài liệu mới
pdf_writer.add_page(pdf_reader_page)
# Ghi tài liệu mới ra tệp PDF
with open(output_pdf_path, 'wb') as output_pdf_file:
pdf_writer.write(output_pdf_file)
# Tăng biến đếm số tệp đã xử lý
file_count[0] += 1
# In ra số thứ tự và tổng số tệp
print(f'[{file_count[0]}/{total_files}] => Đã xử lý tệp: {pdf_name}')
#print(f'Tệp PDF đầu ra: {output_pdf_path}')
except Exception as e:
error_files.append(input_pdf_path) # Thêm đường dẫn tệp bị lỗi vào danh sách error_files
print(f"Lỗi: {str(e)}")
# Hàm để xử lý tất cả các tệp trong thư mục và thư mục con bằng đệ quy
def process_pdfs_in_directory_recursive(directory):
print(f'Bắt đầu xử lý thư mục: {directory}')
total_files = 0
for root, _, files in os.walk(directory):
for filename in files:
if filename.lower().endswith(".pdf"):
total_files += 1
file_count = [0] # Biến đếm số tệp đã xử lý, sử dụng danh sách để tránh lỗi do scope
for root, _, files in os.walk(directory):
for filename in files:
if filename.lower().endswith(".pdf"):
pdf_path = os.path.join(root, filename)
add_pdf_name_as_bookmark(pdf_path, root, file_count, total_files) # Sử dụng thư mục gốc của tệp PDF
# Sử dụng hàm để xử lý tất cả các tệp trong thư mục và thư mục con
directory_to_process = '/mnt/c/Users/DATA/Desktop/bookmark/'
process_pdfs_in_directory_recursive(directory_to_process)
# In ra các tệp PDF bị lỗi nếu có ít nhất một tệp
if error_files:
print("----------------------------------------")
print(f'Các tệp PDF bị lỗi: {len(error_files)}')
for file in error_files:
print(file)
###########################################################################
# Gộp tất cả các file pdf của cả một thư mục và các thư mục con thành 1 file pdf mới
# Bookmark được giữ nguyên tương ứng với nội dung của file gốc
import os
from PyPDF2 import PdfReader, PdfWriter
def merge_pdfs_with_bookmarks(input_dir, output_pdf_path):
# Tạo mảng để lưu trữ vị trí trang và nội dung Bookmark của từng tệp
page_positions = []
# Tạo danh sách error_files trước khi sử dụng nó
error_files = []
try:
# Khởi tạo đối tượng PdfWriter cho tài liệu PDF mới
pdf_writer = PdfWriter()
# Biến để theo dõi tổng số trang
total_pages_so_far = 0
# Duyệt qua tất cả các tệp PDF trong thư mục đầu vào
for root, _, files in os.walk(input_dir):
for filename in files:
if filename.lower().endswith(".pdf"):
pdf_path = os.path.join(root, filename)
# Lấy tên tệp PDF từ đường dẫn
pdf_name = os.path.basename(pdf_path)
# Đọc tài liệu PDF gốc
pdf_reader = PdfReader(pdf_path)
# Duyệt qua từng trang trong tài liệu PDF gốc
for page_num in range(len(pdf_reader.pages)):
pdf_reader_page = pdf_reader.pages[page_num]
# Đặt tên cho Bookmark là tên tệp PDF
bookmark_title = pdf_name
# Tạo đối tượng Bookmark
pdf_writer.add_outline_item(bookmark_title, page_num + total_pages_so_far)
# Thêm trang từ tài liệu gốc vào tài liệu mới
pdf_writer.add_page(pdf_reader_page)
# Lưu vị trí trang và nội dung Bookmark của từng tệp
page_positions.append((bookmark_title, page_num + total_pages_so_far))
# Cập nhật tổng số trang
total_pages_so_far += len(pdf_reader.pages)
# Ghi tài liệu mới ra tệp PDF
with open(output_pdf_path, 'wb') as output_pdf_file:
pdf_writer.write(output_pdf_file)
except Exception as e:
error_files.append(input_pdf_path) # Thêm đường dẫn tệp bị lỗi vào danh sách error_files
print(f"Lỗi: {str(e)}")
# Trả về danh sách error_files và page_positions
return error_files, page_positions
# Sử dụng hàm để gộp tất cả các tệp PDF trong thư mục "input_dir" thành tệp "output_pdf.pdf"
input_dir = '/mnt/c/Users/DATA/Desktop/bookmark/'
output_pdf_path = '/mnt/c/Users/DATA/Desktop/merged_with_bookmarks.pdf'
error_files, page_positions = merge_pdfs_with_bookmarks(input_dir, output_pdf_path)
# In ra các tệp PDF bị lỗi nếu có ít nhất một tệp
if error_files:
print("----------------------------------------")
print(f'Các tệp PDF bị lỗi: {len(error_files)}')
for file in error_files:
print(file)
# Sử dụng page_positions để tham khảo và cập nhật Bookmark cho tệp PDF gộp
# page_positions sẽ có dạng [(bookmark_title, page_num), ...]
Download file py để vào thư mục cần tìm vị trí trang barcode: https://drive.google.com/file/d/1Dv-kt3rv-I4Vzo_jcSlwVtcWIhHcBlEM/view
Cài mở Terminer thư viện trước khi chạy (copy paste enter từng dòng đợi...):
sudo apt-get update -y
sudo apt-get install poppler-utils --fix-missing
sudo apt-get install libzbar-dev -y
sudo apt-get install zbar-tools -y
pip install pyzbar openpyxl
Chạy code:
Lệnh chạy: python3 code128.py
Video:
https://drive.google.com/open?id=1TP8PAKZ2Gq_QzFSIRm71W96bJnzB2OYF&usp=drive_fs